Abstract

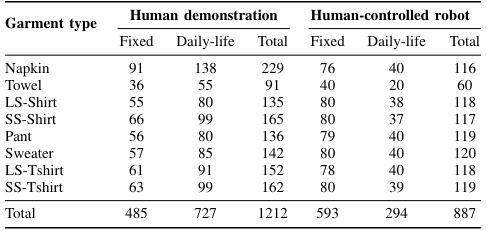
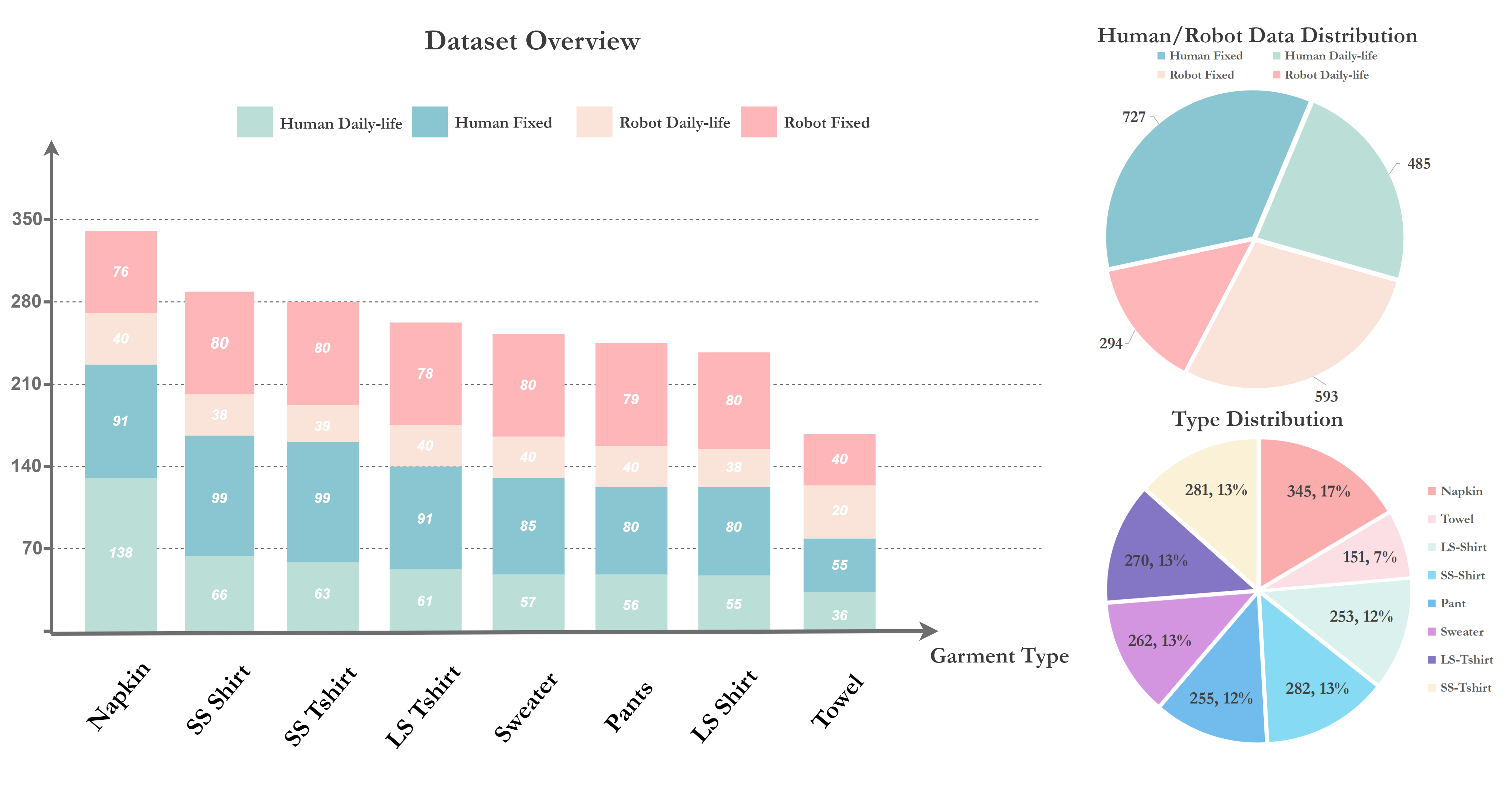
We present Flat'n'Fold, a novel large-scale dataset for garment manipulation that addresses critical gaps in existing datasets. Comprising 1,212 human and 887 robot demonstrations of flattening and folding 44 unique garments across 8 categories, Flat'n'Fold surpasses prior datasets in size, scope, and diversity.
Our dataset uniquely captures the entire manipulation process from crumpled to folded states, providing synchronized multi-view RGB-D images, point clouds, and action data, including hand or gripper positions and rotations.
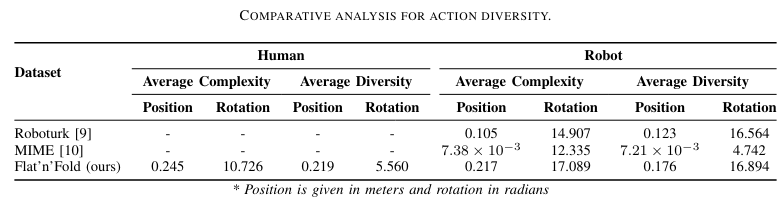
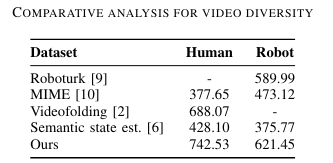
We quantify the dataset's diversity and complexity compared to existing benchmarks and show that our dataset features natural and diverse manipulations of real-world demonstrations of human and robot demonstrations in terms of visual and action information.
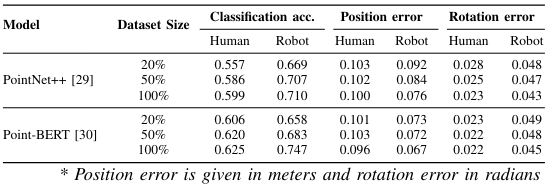
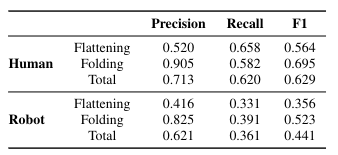
To showcase Flat'n'Fold's utility, we establish new benchmarks for grasping point prediction and subtask decomposition. Our evaluation of state-of-the-art models on these tasks reveals significant room for improvement. This underscores Flat'n'Fold's potential to drive advances in robotic perception and manipulation of deformable objects.