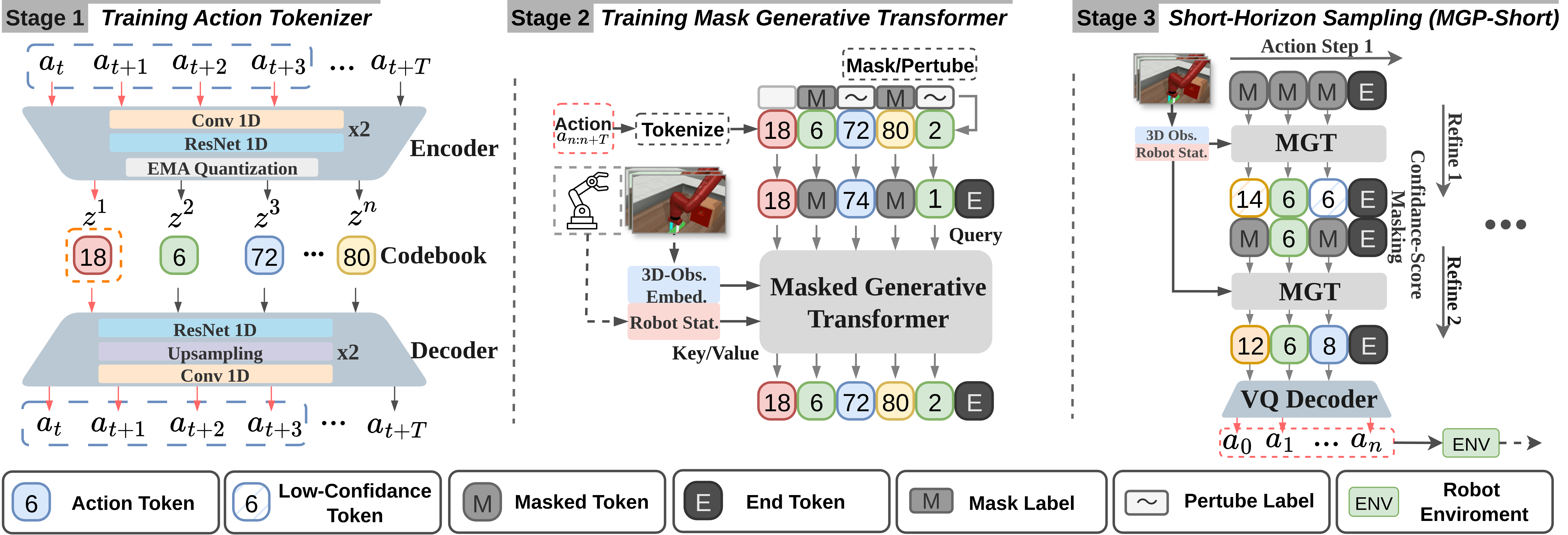
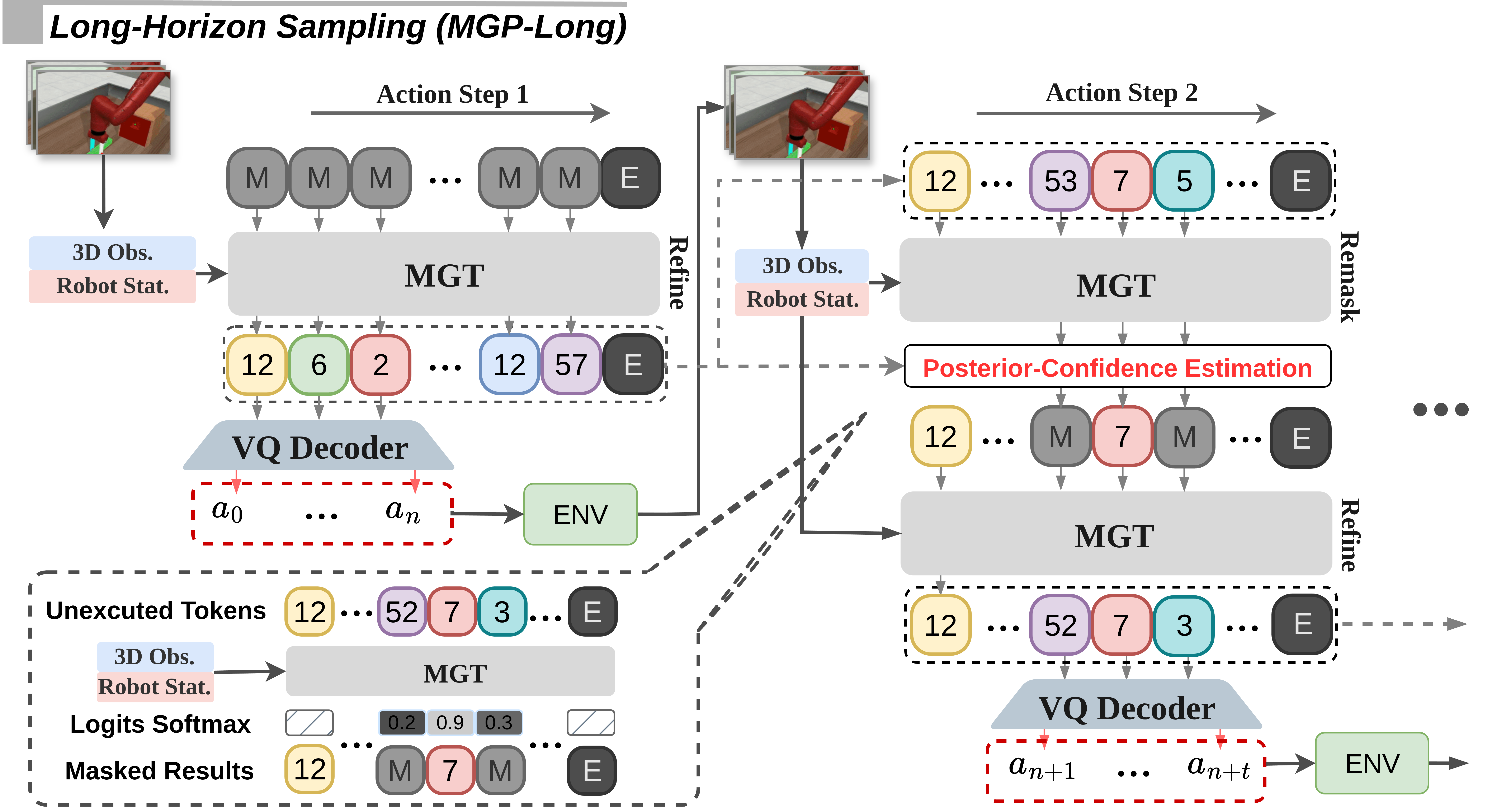
🌟 Overview
Masked Generative Policy (MGP) is a fast, accurate, adaptive, and globally-coherent generative policy for visuomotor imitation learning — combining the efficiency of autoregressive transformers and the flexibility of diffusion models.
MGP is the first masked generative framework for robot imitation learning which achieves low inference latency and high task success rates while supporting rapid plan edits during execution.
Two novel sampling paradigms are proposed:
- MGP-Short – Real-time closed-loop control for Markovian tasks.
- MGP-Long – Delivers globally coherent long-horizon predictions with dynamic adaptation, resilient execution under partial observability, and efficient, flexible replanning for non-Markovian, long-duration, dynamic, and missing-observation environments.